 この記事ではstable diffusion系を使った画像生成で出てくる
この記事ではstable diffusion系を使った画像生成で出てくる
ステップ数、CFG scale、サンプラー
といったパラメータの数々について、
どう言う意味なのか噛み砕きながら紹介したいと思います。
画像生成AI呪文シリーズなるものを作っておりますが、
正直に言うと、パラメータの意味をよく知らずに画像生成AIを使っておりました。
逆に言うと、意味はよく分からなくても使えてしまいます。
もちろん、ステップ数は名前からして何となくイメージできますし、
CFG scaleもどれだけプロンプトに従うかを調整することは
見聞きしておりましたが、これらのパラメータが、
中で何をしているのかが気になったので、調べてまとめます。
画像生成のイメージ
stable diffusionに代表されるような拡散モデルによる画像生成は、
ノイズ除去によって画像を生成していると言うのは
見聞きした方も多いのではないでしょうか。
ざっくりとイメージを書くと下のような感じです。

AIは学習の際に、元となる画像にノイズを加えたノイズ付きの画像に対して、
どうすればノイズを除去して元の画像に戻すことができるのかを学習します。
学習が完了したAIは、てきとうに与えられたノイズ画像から、
(ありもしない)ノイズを除去して、人が作るような絵を生成します。
このノイズ除去の向かう方向を、
画像に紐づいたテキスト情報で「条件付け」することで、
テキストに沿った画像を生み出すことも可能になります。
書籍「ヒトはなぜ絵を描くのか」では、
無いものを補完するのが人が絵を描く時の特徴 として紹介されてましたが、
このAIも ノイズの中から適当に補完してそれっぽい絵を作る と言う意味では、
少し似た部分を感じます。
")
Latent Diffusion Model(LDM)とステップ数
stable diffusionはLatent Diffusion Model(LDM)と呼ばれる拡散モデルを使っていて、
下の図のようなモデルになります。
ごちゃごちゃしてますが、ポイントは 「Denoising U-Net」の部分です。
これが、ノイズ除去 を担当することになります。

"High-Resolution Image Synthesis with Latent Diffusion Models"より引用
LDM自体は画像そのものにノイズ付与・除去するのではなく、
画像を一旦、抽象的な潜在空間に移して、そこでノイズ付与・除去を行います。
こうすることで、ピクセル一つ一つを操作しなくて良くなり計算量が抑えられます。
図の中では画像の抽象的な表現がzで表現されていて、
zが繰り返し「Denoising U-Net」でノイズ除去されていくことで、
出力画像を作っています。
この繰り返しの回数が、「ステップ数」のパラメータです。
条件付けはTransformer
先ほどサラッとテキストで条件付けしてノイズ除去を行うと言いましたが、
それを実現しているのはTransformerです。
Transfomerでは、アテンションと呼ばれる仕組みを導入していて、
クエリ(Q)とキー(K)の類似度で重み付けたバリュー(V)をします。
下の図は、自然言語処理の例ですが、「読む」と言う特徴を知りたかったら、
「読む」のクエリに対して、文中の他の語のキーと比べて類似したところに注目して、それらの特徴(バリュー)を重み付けで足します。

この例では、クエリとキーを同じ文章から持ってきましたが、
クエリをテキスト、キーを画像とすると、
違う種類のもの同士でアテンションを計算することができます。
これをクロスアテンションと言います。
LDMの図のDenoising U-Netをよく見てみると、Q,K,Vと書かれていますよね。
これがTransformerのアテンション機構を指しています。
そして、さらによく見ると、そのアテンション機構に、
外からConditioningの入力があることに気づきます。
このConditioningには例えばテキストなどが与えられ、
テキストで条件づけられたノイズ除去を実現します。
↓Transformerについて詳しくは下の書籍が読みやすく参考になります。(対象は自然言語処理ですが)

より効果的な条件付けを:CFG
ノイズ除去のテキストによる条件付けは、
Transformerのクロスアテンションで実現することが分かりました。
実はstable diffusion(LDM)では、条件付けにさらにひと手間かけています。
それが、Classifier-Free Guidance(CFG)と呼ばれるものです。
謎のパラメーターだったCFG scaleのCFGがこれです。
分類器を使った条件付け
CFGはその名前の通り「分類器を使わない」ものですが、
いきなりそれ単体だと分かりづらいので、
まずは分類器を使ったものを紹介します。
ノイズ除去の過程とは別に、画像の分類を行う分類器を作ったとします。
すると、下の図のように、「犬」の画像を生成したければ、
分類器で「犬」に分類されやすい画像に向かえば良さそうです。
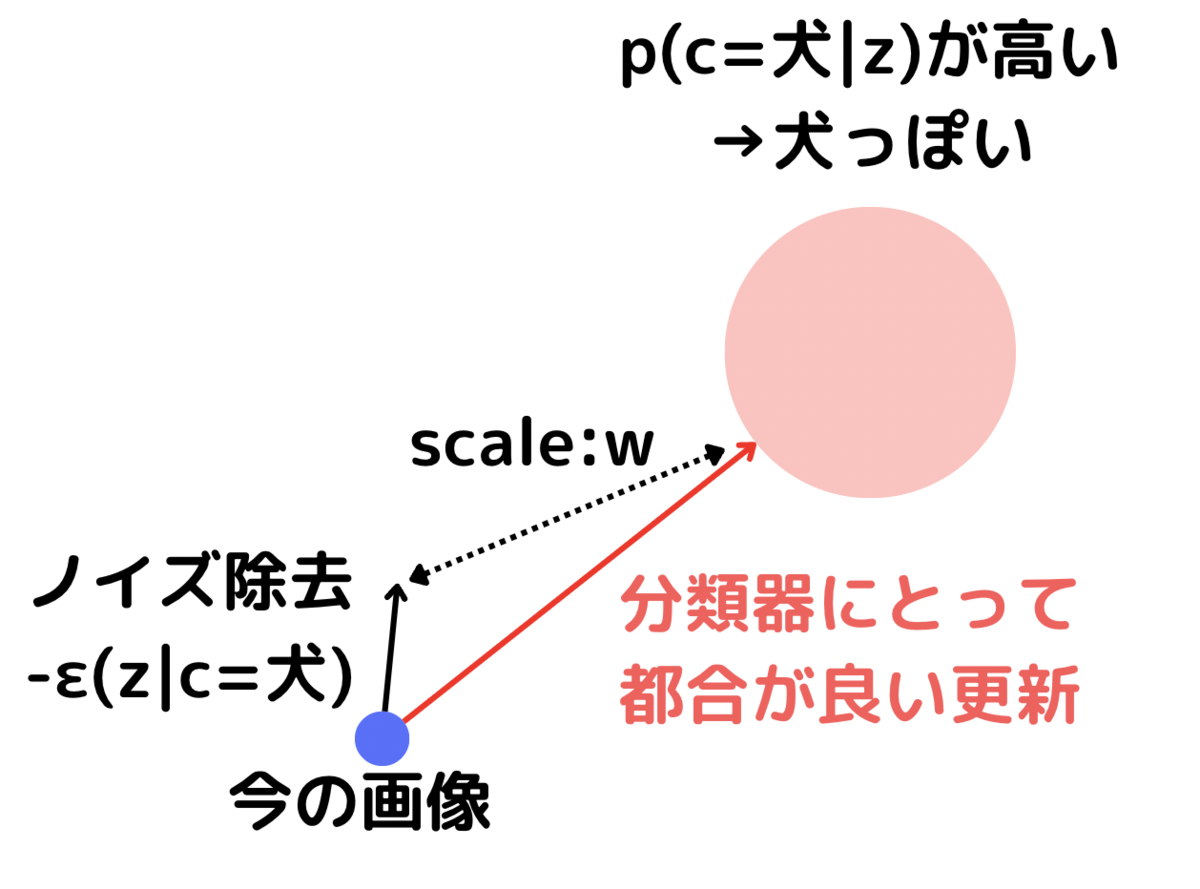
ここで、ノイズ除去の進む方向と、
分類器にとって都合の良い方向の二つの方向が出てきました。
そこで、このどちらを重視するの割合を決めるパラメータが必要になります。
このパラメータを分類器側に傾けると
より「犬」と分かりやすい画像を出力するでしょう。
分類器を使わずに条件付けの強化
分類器を別に学習するのはコストがかかります。
CFGでは分類器を使わずに上と同じような効果を得ることが目指されています。
そのアイディアのキーになるのは、逆確率でしょう。
LDMでは条件つきでのノイズ除去の過程p(z|c)を学習しています。
これの逆確率p(c|z)は、画像(抽象表現)の条件cの確率であり、
分類器として働きます。
ベイズの公式から逆確率は、
次のように無条件の分布を使って計算できます。
というわけで、ノイズ除去のためにp(z|c)を学習するときに、
ついでに無条件のp(z)も学習しておけば、
作ってない仮想的な分類器を使って、
先ほどと同じこと同じことができそうです。
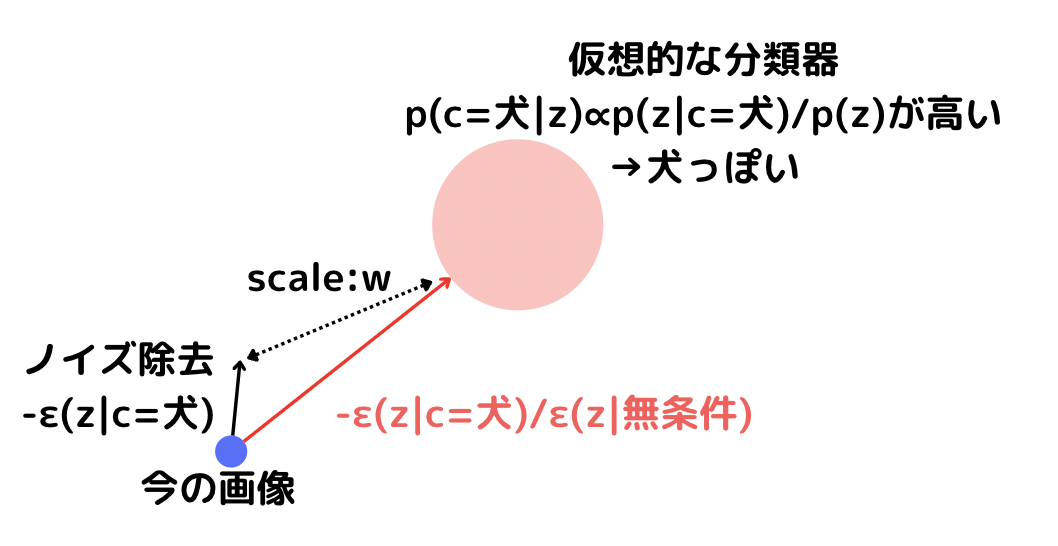
上の図はCFGのイメージです。
条件付きのεと条件無しのεを使って、
仮想的な分類器にどれだけ寄せに行くかをパラメーターで調整します。
このパラメータこそがCFG scaleです。
CFG scaleが大きいほど、仮想的な分類器に都合が良い
プロンプトに沿った分かりやすい画像が生成されやすくなります。
矢印にどう従うかがサンプラーの役目
CFG scaleではオリジナルの条件付きのノイズ除去の方向と、
仮想的な分類器に合わせに行く方向のどちらを重視するか、
をコントールしました。
結果として、それぞれの方向を足し合わせた一つの矢印が得られます。
この矢印は最適化問題でいうところの勾配です。
最適化問題でも勾配を登るためのアルゴリズムが様々あるように、
勾配が決まってもその勾配の登り方は様々です。
矢印が与えられた時に、
実際にどのように勾配を登るのかを決めるのがサンプラーです。
船で例えるなら、CFGが方位磁石でサンプラーが操舵手ですね。
沢山のステップをかけて、じっくり着実に登るタイプのサンプラーもいれば、
大雑把に駆け上がるタイプのサンプラーもいます。
登り方によって到達する地点も変わってくるので、
サンプラーによって生成される画像の個性が出ることになります。
参考文献:Classifier-Free Diffusion Guidance
まとめ
stable diffusionのざっくりとして仕組みの話から、
ステップ数、CFG scale、サンプラーなどのパラメーターが
何者なのかについて紹介しました。
細かいことを知らなくても動くのは素晴らしいことですが、
中身を知っておくとより調整が楽しくなりますよね。
おかげさまで「Novel AI ポーズ集」が、
Amazonのイラスト集カテゴリでベストセラー1位が続いております。
一瞬だけかと思ったら、かなり長い期間続いていてとても驚いております。
Kindle Unlimited読み放題の対象ですので、
登録済みの方はお気軽にお読み頂けますと幸いです。
")